

11·
10 months agoIt’s primary a writing platform with built-in monetization options and the ability to self host. We switched to it from Substack. It’s been fantastic to use and operate. Super slick.

It’s primary a writing platform with built-in monetization options and the ability to self host. We switched to it from Substack. It’s been fantastic to use and operate. Super slick.

It depends on many factors including:
So you’re right that you make an initial guess and go from there.
Many tools/sites/projects will have minimum system requirements and you can get an idea of minimums using those stats. Some frameworks might even have guidelines available. The one I use most often for example has a configurable memory footprint. So that’s a datapoint I personally use.
If they’re all the same type of site (example Ghost blogs) using the same setups then it’s often less intense since you can pool resources like DBs and caching layers and go below minimum system requirements (which for many sites include a DB as part of the requirements).
Some sites might be higher traffic but use fewer resources, others might be the inverse.
Then there’s also availability. Are these sites for you? Is this for business? What kind of uptime guarantee do you need? How do you want to monitor that uptime and react to needs as they arrive/occur?
The best way to handle this is in a modern context also depends on how much and what style of ops you want to engage in.
Auto-scaling on an orchestration platform (something like K8S) or cloud-provider auto-scaling of VMs or something else? Do you want deployments managed as-code via version control? Or will this be more “click Ops”. No judgement here just a thing that will determine which options are best for you. I do strongly recommend on some kind of codified, automated ops workflow - especially if it’s 25 sites, but even with just a handful. The initial investment will pay for itself very quickly when you need to make changes and are relived to have a blueprint of where you are.
If you want to set it and forget it there are many options but all require some significant initial configuration.
If you’re ok with maintenance, then start with a small instance and some monitoring and go from there.
During setup and staging/testing the worst that can happen is your server runs out of resources and you increase its available resources through whatever method your provider offers. This is where as-code workflows really shine - you can rebuild the whole thing with a few edits and push to version control. The inverse is also true - you can start a bit big and scale down.
Again, finding what works for you is worth some investment (and by works I don’t just mean what runs, but what keeps you sane when things go wrong or need changing).
Even load testing, which you mentioned, is hard to get right and can be challenging to instrument and implement in a way that matches real-world traffic. It’s worth doing for sites that are struggling under load, but it’s not something I’d necessarily suggest starting with. I could be wrong here but I’ve worked for some software firms with huge user bases and you’d be surprised how little load testing is done out there.
Either way it sounds like a fun challenge with lots of opportunities for learning new tricks if you’re up for it.
One thing I recommend avoiding is solutions that induce vendor lock-in - for example use OpenTofu in lieu of something like CloudFormation. If you decide to use something like that in a SaaS platform - try not to rely on the pieces of the puzzle that make it hard (sticky) to switch. Pay for tools that bring you value and save time for sure, but balance that with your ability to change course reasonably quickly if you need to.
As per my other comment - the algorithm is only part of it.
A big aspect however is the slickness and ease-of-onboarding for mega-Corp apps. It’s a thing that would relatively easy to begin work on.
I’ve seen first hand the amount of time and money even growth-stage startups spend on onboarding and have lots of first-hand reports from peers at the big girls - it’s a critical part of success. Make it easy to get started and easy to stay using.
It’s missing from most fediverse experiences. Pixelfed being a serious contender for an on-boarding rethink.
“time-to-value” - we want that as low as possible.
Never used your project but don’t let this thread get you down.
Clearly OP loves it - don’t let those who don’t know it or don’t like it be the voices that ring loudest in your ears even if they hurt the most.
I worked professionally in open source at a company with lots of funding. The tools I worked on were used by millions and millions.
Every negative comment hurt so much. Every angry user I wanted to talk to. Most of them wanted to TALK AT me. It all hurt. And I was being paid. The engineers on my teams were burnt by the community time and time again.
If you love what you’re doing and you have a growing or happy audience - stay the course. Listen to criticism, decide if you agree (and maybe take some time when it hurts because the criticism might be valid), make a decision and move on.
Also, and this is going to be tough, maybe think about expanding or modifying what you mean when you say making Lemmy accessible for everyone.
Do you mean making a UI that will become the majority default or making a UI that brings some features (or perspective) for users who see value in those features? Trying to make something for everyone in a pond as small as the fediverse, where there are already a plethora of options is a big lift.
Above all, do you. And that includes this comment which I encourage you to promptly ignore. ;)

Pros:
Cons:
I’m on iOS and do the same thing.
The WireGuard app has a setting to “connect on demand”. It’s in the individual connections/configurations.
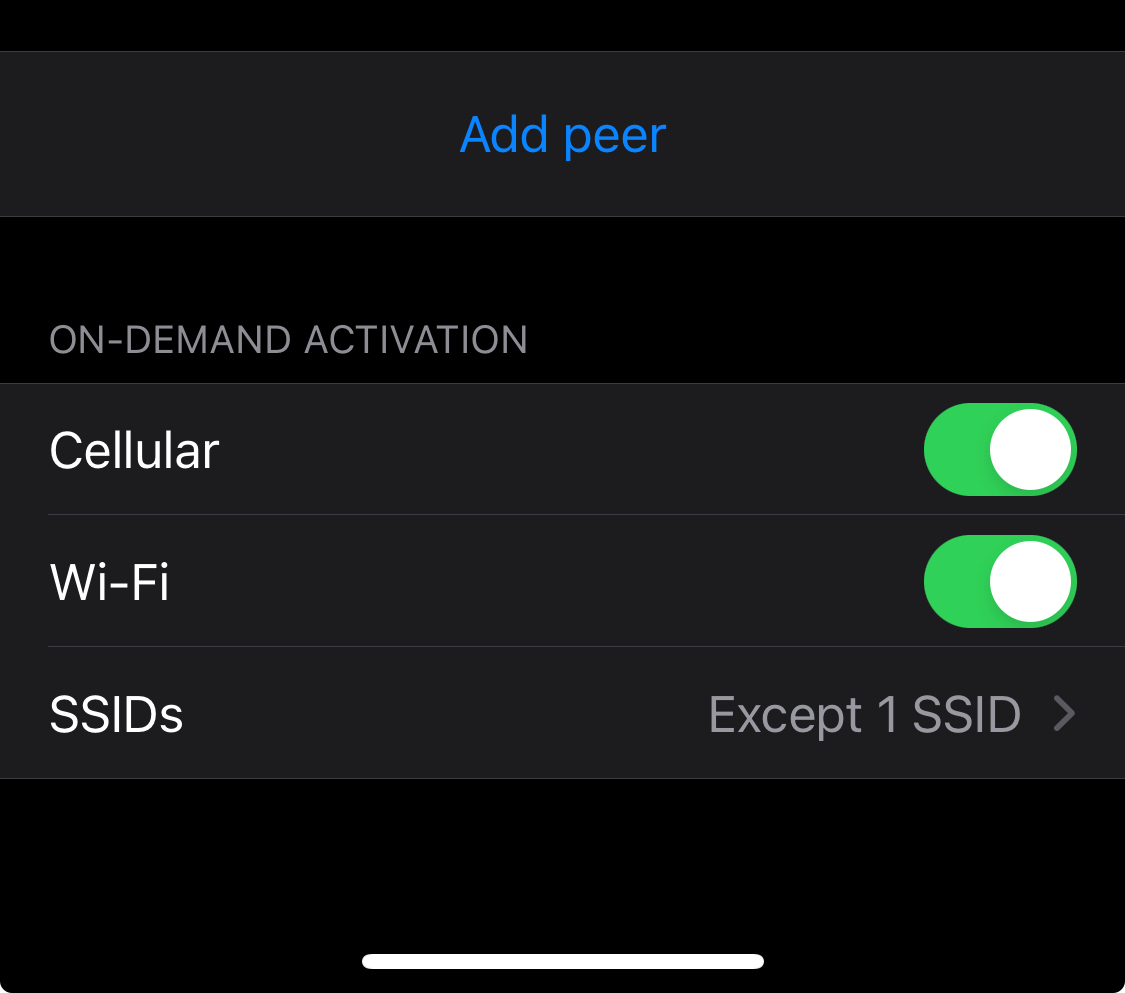
You can then set either included or excluded SSIDs. There’s also an option to always connect when you’re on mobile/cellular data.
I imagine the Android app is similar.
Neat, I’ll have to look it up. Thanks for sharing!
Nextcloud isn’t exposed, only a WireGuard connection allows for remote access to Nextcloud on my network.
The whole family has WireGuard on their laptops and phones.
They love it, because using WireGuard also means they get a by-default ad-free/tracker-free browsing experience.
Yes, this means I can’t share files securely with outsiders. It’s not a huge problem.
Update: I went and had a look and there’s a Terraform provider for OPNSense under active development - it covers firewall rules, some unbound configuration options and Wireguard, which is definitely more than enough to get started.
I also found a guide on how to replicate pfBlocker’s functionality on OPNSense that isn’t terribly complicated.
So much of my original comment below is less-than-accurate.
OPNSense is for some, like me, not a viable alternative. pfBlockerNG in particular is the killer feature for me that has no equivalent on OPNSense. If it did I’d switch in a heartbeat.
If I have to go without pfBlockerNG, then I’d likely turn to something that had more “configuration as code” options like VyOS.
Still, it’s nice to know that a fork of a fork of m0n0wall can keep the lights on, and do right by users.
If you backup your config now, you’d be able to apply the config to CE 2.7.x.
While this would limit you to an x86 type device, you wouldn’t be out of options.
I am an owner of an SG-3100 as well (we don’t use it anymore), but that device was what soured me on Netgate after using pfSense on a DIY router at our office for years…
I continued to use pfSense because of the sunk costs involved (time, experience, knowledge). This is likely the turning point.
Cluster of Pi4 8GBs. Bought pre-pandemic; love the little things.
Nomad, Consul, Gluster, w/ TrueNas-backed NFS for the big files.
They do all sorts of nifty things for us including Nightscout, LanguageTool OSS, monitoring for ubiquiti, Nextdrive, Grafana (which I use for home monitoring - temps/humidity with alerts), Prometheus & Mimir, Postgres, Codeserver.
Basically I use them to schedule dockerized services I want to run or am interested in playing with/learning.
Also I use Rapsberry Pi zero 2 w’s with Shairport-sync (https://github.com/mikebrady/shairport-sync ) as Airplay 2 streaming bridges for audio equipment that isn’t networked or doesn’t support AirPlay 2.
I’m not sure I’d buy a Pi4 today; but they’ve been great so far.
As someone who runs a self-hosted mail service (for a few select clients) in AWS, this comment ring true in every way.
One thing that saved us beyond SPF and DKIM was DMARC DNS records and tooling for diagnosing deliverability issues. The tooling isn’t cheap however.
But even then, Microsoft will often blacklist huge ranges of Amazon EIPs and if you’re caught within the scope of that range it’s a slow process to fix.
Also, IP warming is a thing. You need to start slow and at the same time have relatively consistent traffic levels.
Is it worth it, not really no - and I don’t think I’d ever do it again.
You’ve described Ghost. Subscriptions for content are a first class citizen.